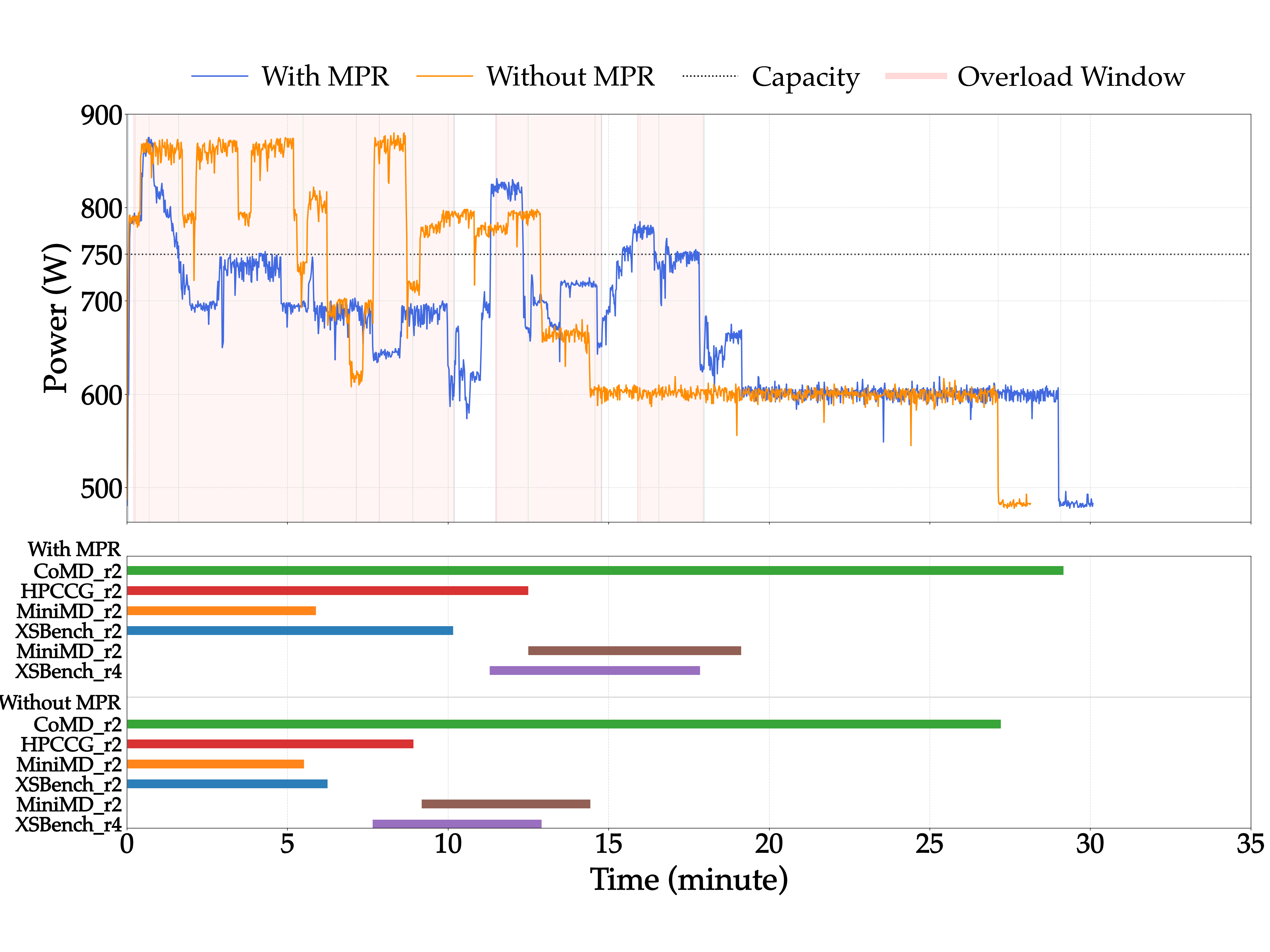
Developed a Python-based framework for detecting and mitigating power overload events in HPC clusters. This work was completed as part of my Graduate Research Assistant role at the University of Texas at Arlington, where I extended the main idea from a previous conference paper into a practical implementation that could run on a live HPC cluster.
My Role : Core Developer
Tech Stack : Python, Bash/Shell, Slurm, Socket.IO
Platform : HPC Cluser on Linux
The framework integrates with the Slurm job scheduler to monitor active workloads and collects real-time power telemetry from an external PDU. When a power overload is detected, the system applies CPU-frequency scaling across the cluster to reduce power consumption and later restores normal frequency settings once the overload condition is resolved.
A key component of the framework is the Market-based Power Reduction, or MPR, mechanism. In this setup, each user submits a bid that represents how much compensation they would require for allowing their job to be slowed down. The HPC manager then selects power-reduction actions by slowing selected jobs and compensating users for the performance impact. This bidding model also allows users to abstract their private slowdown cost: instead of revealing the actual cost or sensitivity of their job to the HPC manager, users can encode that preference through their bid.